

 Breve guida per conoscere i crawler e gli elementi del file robot.txt
Breve guida per conoscere i crawler e gli elementi del file robot.txt
Con il termine crawler si stanno ad indicare dei programmi o script automatici che vengono utilizzati dalla maggior parte dei motori di ricerca (come Google o Bing) per eseguire una scansione dei siti web in modo da indicizzarne i contenuti. Attraverso una scansione continua della rete i motori di ricerca possono così fornire risultati di ricerca aggiornati praticamente in tempo reale.
Tuttavia una “visita costante” dei siti da parte dei motori di ricerca può in alcuni casi portare anche a diverse centinaia di richieste al minuto. Tale attività potrebbe mettere sotto stress il vostro server causando talvolta eccessiva lentezza nel caricamento delle pagine e nei casi peggiori non raggiungibilità del vostro sito web.
Per evitare che ciò accada è possibile fornire delle istruzioni ai crawler dei motori di ricerca ed escluderne alcuni se non siete interessati alla loro indicizzazione. Una pratica molto comune consiste quindi nell’inserire alcune regole all’interno del file robots.txt
Una di queste, può essere la direttiva Crawl-delay che permette di indicare il numero di secondi da attendere tra una richiesta e quella successiva.
Gli elementi del file robot.txt
Ma andiamo per ordine. Di seguito riportiamo gli elementi chiave di cui può essere composto un file robots.txt:
- User-agent: serve ad indicare il nome dello spider verso il quale sono rivolte le istruzioni.
- Disallow: serve ad indicare i file o le directory ai quali lo spider non deve accedere. Tale campo può anche essere lasciato vuoto se non vi è necessità di “vietare” alcune zone del sito ai motori di ricerca.
- Allow: consente la scansione di un percorso particolare.
- Crawl-delay: serve ad indicare il numero di secondi che uno spider deve attendere tra una richiesta e quella successiva. Se tale parametro non viene impostato vuol dire che non vi sono direttive a riguardo. Tipicamente assegnare il valore 1 a questo parametro può non portare a benefici se sul server sono presenti diversi siti web.
- Visit-time: indica l’intervallo orario all’interno del quale effettuare la scansione.
- Request-rate: indica il numero massimo di pagine da visitare per intervallo di tempo.
- Sitemap: serve ad indicare la presenza ai motori di ricerca di una sitemap XML.
La sintassi per scrivere queste istruzioni permette l’utilizzo di espressioni regolari e segue le seguenti regole:
- “*” corrisponde a qualsiasi sequenza di carattere (zero or più caratteri).
- “?” corrisponde a un qualsiasi carattere.
- “\” Serve a “bloccare” un carattere speciale.
- [<set>] corrisponde a qualsiasi carattere indicato tra le parentesi quadre.
- [!<set>] or [^<set>] corrisponde a qualsiasi carattere non presente tra le parentesi quadre.
Riportiamo alcuni esempi di possibili istruzioni che è possibile inserire nel file robot.txt:
User-agent: MSNBot Disallow: /prova1.html Disallow: /cache Crawler-delay: 5
In questo caso indichiamo ai crawler di MSNBot di non indicizzare il file prova1.html e la cartella cache.
Inoltre devono attendere 5 secondi tra una richiesta e quella successiva.
E’ anche possibile escludere un particolare crawler dall’indicizzare il nostro sito. In questo caso è sufficiente utilizzare la seguente direttiva:
User-agent: Yandex Disallow: *
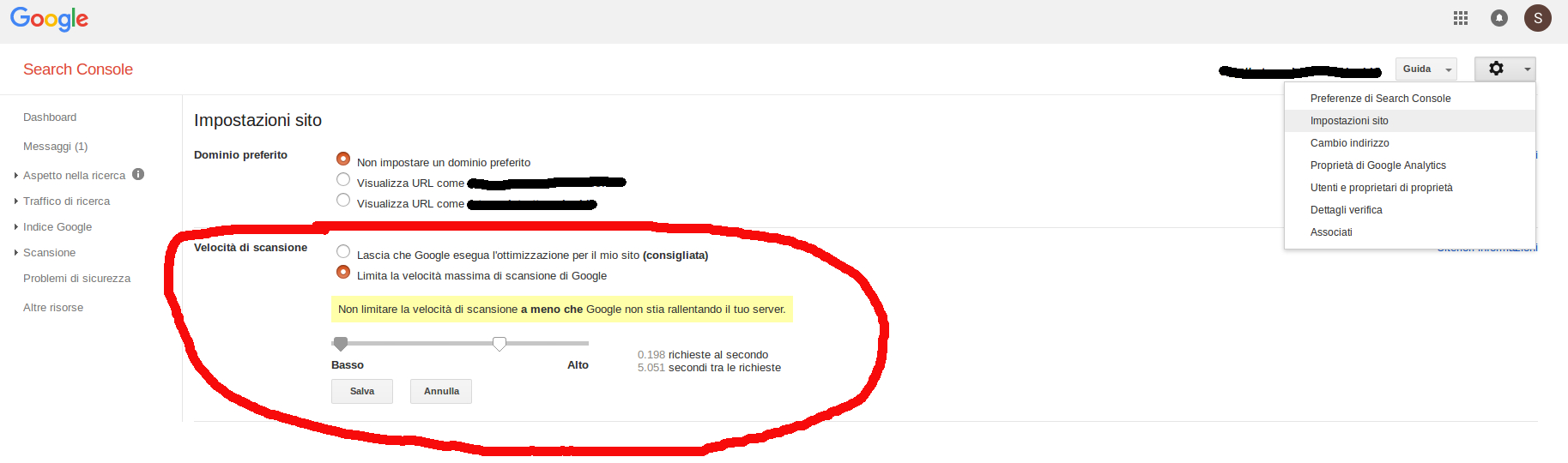 Alcuni motori di ricerca come Google o Bing dispongono di un pannello di controllo avanzato che permette di gestire diverse funzionalità.
Alcuni motori di ricerca come Google o Bing dispongono di un pannello di controllo avanzato che permette di gestire diverse funzionalità.
Ad esempio Googlebot non supporta il Crawl-delay, pertanto è necessario impostarlo tramite gli strumenti di Google Webmaster Tools che trovate in “Impostazioni sito”. Questa impostazione sarà valida per un tempo massimo di 90 giorni.
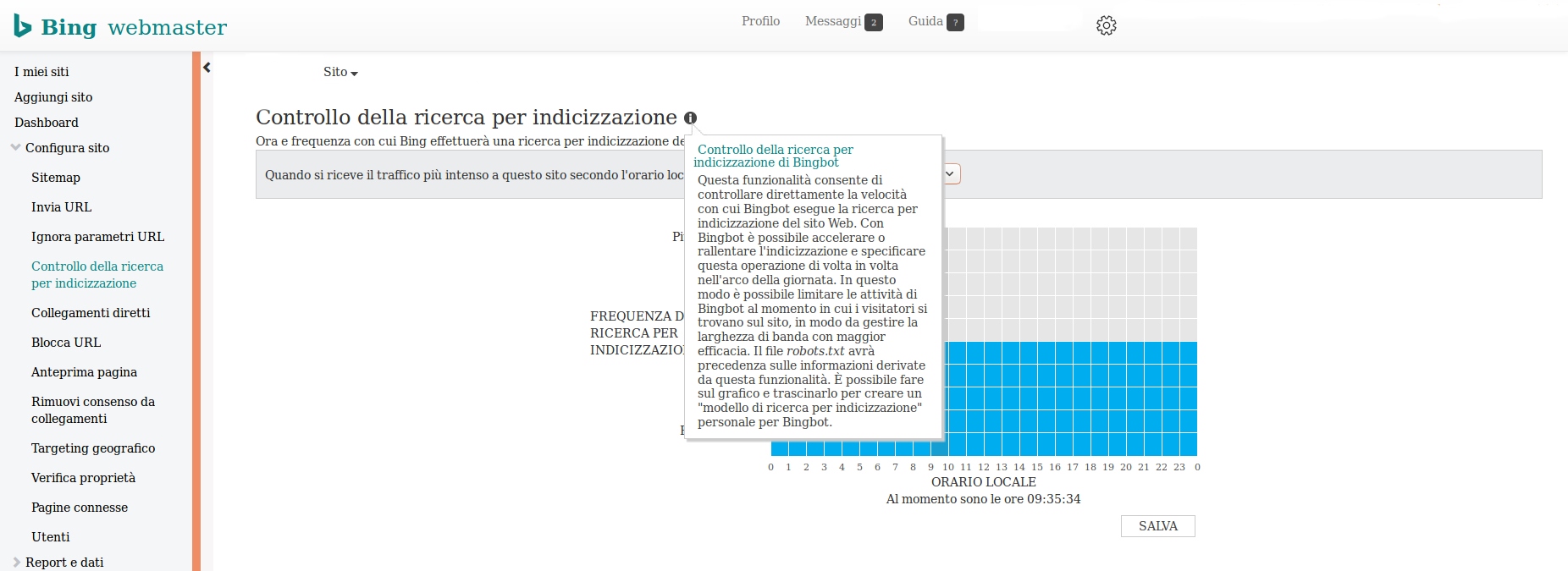 Anche Bing permette di gestire la velocità dei crawler attraverso il proprio pannello. Sarà possibile indicare la velocità di indicizzazione che i crawler devono rispettare ogni ora nell’arco della giornata. Ad esempio, se il nostro sito ha un traffico elevato tra le 12:00 e le 18:00, possiamo diminuire la velocità in questa fascia oraria per evitare un sovrautilizzo delle risorse del server. A differenza di Google, Bing da priorità alle regole inserite nel file robots.txt
Anche Bing permette di gestire la velocità dei crawler attraverso il proprio pannello. Sarà possibile indicare la velocità di indicizzazione che i crawler devono rispettare ogni ora nell’arco della giornata. Ad esempio, se il nostro sito ha un traffico elevato tra le 12:00 e le 18:00, possiamo diminuire la velocità in questa fascia oraria per evitare un sovrautilizzo delle risorse del server. A differenza di Google, Bing da priorità alle regole inserite nel file robots.txt
Un ultimo consiglio: tenete presente che il file robots.txt è un file accessibile a tutti. Quindi è consigliabile non inserire directory o file “segreti”.


